
Why Traditional Predictive Maintenance ROI Models Leave Money on the Table
Most predictive maintenance business cases are built by maintenance teams and reviewed by plant engineering. That origin shapes what gets counted — and what doesn't. The standard model quantifies maintenance cost reduction: fewer emergency repairs, less overtime, lower parts consumption. It's a real benefit, and published benchmarks confirm it.
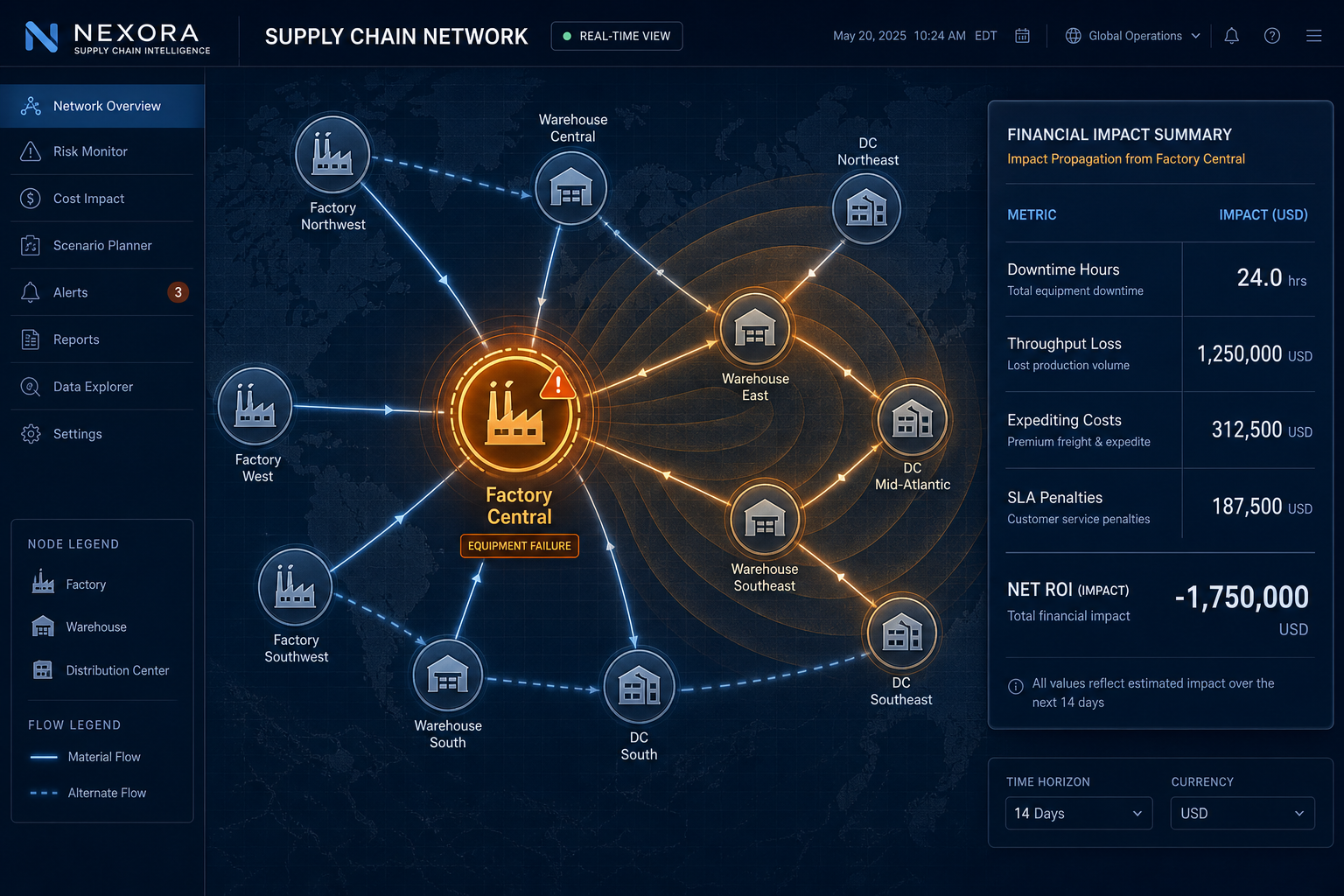
What the maintenance-only frame misses is the supply chain disruption cost that cascades from every unplanned equipment failure. Stockouts from interrupted production runs. Spot freight and expediting premiums paid to recover schedule. SLA penalties triggered when customer commitments slip. Inventory write-downs on time-sensitive materials. These costs don't appear in the CMMS. They show up in the TMS, the order management system, and the demand planning model — systems that maintenance teams don't own and typically don't consult when building a business case.
The result is a systematic undercount. A model built on maintenance savings alone typically captures less than half of the actual financial benefit that a predictive maintenance program delivers. For supply chain planners, this isn't just a measurement problem — it's a budget problem. Underbuilt ROI models fail to secure scaling investment, which is precisely why so many programs remain confined to isolated pilots.
The Two Cost Layers of Equipment Downtime
A complete downtime impact analysis separates costs into two layers. Layer 1 is what maintenance teams already measure. Layer 2 is what supply chain planners must add to produce a defensible business case.

Layer 1 covers the immediate, asset-level costs of a failure event: lost throughput revenue during the downtime window, the premium paid for emergency repair versus a planned maintenance intervention, and overtime labor to recover lost production. These figures are recoverable from production records and maintenance logs.
Layer 2 covers the supply chain disruption costs that propagate downstream from that same event. These are the costs that make equipment reliability a supply chain problem, not just a maintenance problem.
| Cost Layer | Cost Type | Where It Appears | Who Typically Quantifies It |
|---|---|---|---|
| Layer 1 — Direct | Lost throughput revenue | Production records / ERP | Operations / Finance |
| Layer 1 — Direct | Emergency repair premium over planned repair cost | CMMS / Maintenance budget | Maintenance |
| Layer 1 — Direct | Overtime labor to recover production | HR / Payroll systems | Operations |
| Layer 2 — Indirect | Stockouts and inventory write-downs from disrupted runs | ERP / Inventory management | Supply chain planner |
| Layer 2 — Indirect | Expediting and spot freight premiums | TMS / Freight audit | Supply chain planner / Logistics |
| Layer 2 — Indirect | SLA penalty exposure per disruption event | Order management system / Contracts | Supply chain planner / Commercial |
| Layer 2 — Indirect | Customer churn risk from repeated service failures | CRM / Commercial reporting | Sales / Supply chain planner |
The scale of Layer 1 alone is significant in heavy-asset industries. In oil and gas, unplanned downtime costs hundreds of thousands of dollars per hour on average and can exceed tens of millions of dollars per year. Comparable magnitudes apply across heavy manufacturing, steel, chemicals, and process industries — any environment where production is capital-intensive and restart costs are high. When Layer 2 costs are added, the total impact is substantially larger.
Conducting an Equipment Downtime Impact Analysis: Data Inputs and Calculation Method
Before building the ROI model, you need a baseline downtime impact figure for each critical asset. This requires pulling cost data from multiple systems — not from the CMMS alone. The following inputs are required for a complete analysis.
- Baseline unplanned downtime hours per asset per year. Pull from CMMS or production logs. Segment by asset class and site. Distinguish unplanned failures from planned maintenance windows — only unplanned events are relevant to this analysis.
- Revenue or throughput value per downtime hour. Pull from ERP. Calculate as: (annual throughput revenue ÷ available production hours). For multi-product lines, use the weighted average contribution margin per hour rather than gross revenue to avoid overstating the impact.
- Emergency repair cost premium versus planned repair cost. Pull from CMMS and maintenance budget records. The premium is typically the difference between the emergency call-out rate (including parts availability at spot pricing) and the cost of the same repair performed on a scheduled basis. This is the maintenance-side savings input.
- Expediting and spot freight cost per disruption event. Pull from TMS or freight audit records. Identify shipments flagged as expedited or spot-procured following a production disruption. Calculate average cost premium over standard freight for the same lane and weight class.
- SLA penalty exposure per disruption. Pull from order management system and customer contracts. Identify which customer commitments are at risk when a specific asset goes down, and what the contractual penalty or service credit exposure is per late or short delivery event.
- Safety stock buffer implications. Pull from demand planning system. Quantify how much additional safety stock is currently being carried to buffer against equipment unreliability on critical production assets. This represents a working capital cost that predictive maintenance can partially reduce.
- Inventory write-down exposure. Pull from ERP inventory records. Identify materials or WIP that are written down or scrapped following unplanned production stoppages, particularly in industries with short shelf life or tight processing windows (food and beverage, specialty chemicals, precision components).
| Input Variable | Source System | Calculation Note |
|---|---|---|
| Unplanned downtime hours / asset / year | CMMS, production logs | Unplanned failures only; exclude scheduled maintenance |
| Throughput value per downtime hour | ERP | Use contribution margin per hour, not gross revenue |
| Emergency repair premium vs. planned repair | CMMS, maintenance budget | Spot parts pricing + call-out rate differential |
| Expediting and spot freight cost per event | TMS, freight audit | Premium over standard freight for same lane/weight |
| SLA penalty exposure per disruption | Order management, contracts | Per-event exposure × historical disruption frequency |
| Safety stock buffer for equipment unreliability | Demand planning system | Working capital cost of excess buffer inventory |
| Inventory write-down per disruption event | ERP inventory records | Particularly relevant for perishable or time-sensitive materials |
Building the ROI Model: Formula, Inputs, and Output Metrics
Once you have the downtime impact baseline, the ROI model follows a straightforward structure. The formula has three benefit components and one cost component.
| Component | Description | Typical Source |
|---|---|---|
| Benefit A: Avoided downtime cost | (Avoided unplanned downtime hours × throughput value per hour) + (Emergency repair premium × avoided failure events) | ERP + CMMS baseline |
| Benefit B: Avoided supply chain disruption cost | Avoided expediting and spot freight + avoided SLA penalties + reduced safety stock carrying cost + avoided inventory write-downs | TMS + order management + demand planning |
| Benefit C: Maintenance cost reduction | 18–31% reduction in total maintenance spend from predictive vs. preventive approach (published benchmark range) | Maintenance budget |
| Cost: Program investment | Sensor/IoT deployment + platform subscription + CMMS/ERP integration + internal labor for ramp-up | IT, procurement, operations |
The net annual benefit is: (Benefit A + Benefit B + Benefit C) − Annual program cost. Apply this across a three-year horizon to produce the three primary output metrics.
- Payback period: The number of months until cumulative net benefit exceeds cumulative program cost. For most industrial deployments, this falls between 18 and 36 months when all three benefit components are included.
- 3-year NPV: Net present value of the benefit stream minus the investment, discounted at your organization's hurdle rate. This is the metric most finance teams require for capital approval.
- Annual cost avoidance: The steady-state annual benefit once the program is fully deployed. This is the most useful metric for S&OP and operational planning discussions because it translates directly into service level risk reduction and working capital release.
On the maintenance cost reduction side, predictive maintenance reduces overall maintenance costs by 18% to 31% compared to traditional methods. This is a real and meaningful benefit — but for most industrial organizations, it is the smaller of the two benefit components. The supply chain disruption avoidance value (Benefit B) typically exceeds maintenance cost reduction once SLA penalties, expediting costs, and safety stock implications are fully quantified.
Industry Benchmarks: Downtime Reduction Rates and Real Deployment Outcomes
Grounding your ROI model in published benchmarks is essential for finance credibility. The following figures are drawn from verified sources and are appropriate for use as reference inputs in a business case.
| Benchmark | Figure | Source | Applicability Note |
|---|---|---|---|
| Maintenance cost reduction, predictive vs. traditional | 18–31% | IBM | Applies to total maintenance spend; use as Benefit C input |
| Unplanned downtime cost, oil and gas | Hundreds of thousands per hour; can exceed tens of millions per year | IBM | Anchor benchmark for heavy-asset industries; use as directional reference, not a cross-industry average |
| Machine downtime avoided, BlueScope Steel (global) | 1,950+ hours across multiple sites | Siemens / BlueScope | Full-scale deployment outcome; use as supply-chain-scale proof point |
| Complete process stops avoided, BlueScope Steel | 53 stops avoided globally | Siemens / BlueScope | Directly quantifies supply chain continuity impact, not just maintenance savings |
| Predictive maintenance market size (2022) | $5.5 billion | IoT Analytics | Market context; confirms technology maturity and vendor availability |
| Projected market CAGR through 2028 | 17% | IoT Analytics | Indicates sustained investment in the category |
| Companies capturing Industry 4.0 value at scale | ~30% | McKinsey | Contextualizes why most PdM programs remain at pilot stage |
The BlueScope Steel deployment is particularly useful as a supply-chain-scale reference point. BlueScope avoided over 1,950 hours of machine downtime across multiple sites worldwide — including 1,200 hours in Australia and 750 hours in other regions — and 53 complete process stops, using Siemens Senseye Predictive Maintenance. In steel manufacturing, each process stop carries restart costs and production losses that extend well beyond the downtime window itself. The 53 avoided process stops represent a supply chain continuity outcome, not just a maintenance outcome.
In the best case we do not have to stop a line — which would create waste and unnecessary greenhouse emissions — but can manage maintenance during the production. — BlueScope Steel Digital Transformation Manager, cited in Siemens case study
The market adoption context from McKinsey is equally important for framing the business case internally. Only about 30% of companies are capturing value from Industry 4.0 solutions at scale today, with most organizations stuck in what McKinsey describes as 'pilot purgatory.' A well-structured, supply-chain-framed ROI model is the primary tool for breaking out of that cycle — it provides the business value clarity that scaling decisions require.
Four Modeling Pitfalls Supply Chain Planners Must Avoid
ROI models for predictive maintenance fail in predictable ways. These four pitfalls are the most common — and the most damaging to business case credibility.
- Using only maintenance cost savings as the benefit numerator. This is the foundational error. A model built on Benefit C alone (18–31% maintenance cost reduction) will produce a payback period that is 2–4× longer than the full-scope model. Finance teams reviewing a maintenance-only case will compare the investment against the maintenance budget — a relatively small cost pool. The supply chain disruption avoidance component connects the investment to a much larger cost base.
- Ignoring ramp-up timelines. Predictive maintenance programs do not deliver full downtime reduction from day one. Sensor calibration, model training, and alert threshold tuning typically require 6 to 12 months before the system is producing reliable predictions at production scale. A model that assumes full benefit from month one will show a payback period that is unrealistically short — and will fail to survive a finance review when actual year-one results come in below projection.
- Omitting integration costs for CMMS and ERP connection. The platform subscription is rarely the largest cost item. Integration between the predictive maintenance platform, the CMMS (for work order generation), and the ERP (for parts inventory and throughput data) is consistently underestimated in initial business cases. Get a scoped integration estimate from IT before finalizing the cost side of the model.
- Failing to account for false-alarm rates in early deployment. During the first months of deployment, alert thresholds are not yet calibrated to the specific asset and operating environment. False alarms generate unnecessary maintenance interventions, consume technician time, and can erode operator trust in the system. This labor cost is real and must be included in the year-one cost calculation. Many organizations struggle to move predictive maintenance beyond isolated use cases precisely because fragmented data and alert overload make early-stage results look worse than the mature program will perform. A model that accounts for this ramp-up dynamic will be more accurate and more credible.
Implementation Timeline and Ramp-Up: What the ROI Model Must Reflect
A realistic implementation timeline is essential for producing a credible multi-year model. The following arc is grounded in documented deployment experience.
| Phase | Typical Duration | Cash Flow Implication | Key Activities |
|---|---|---|---|
| Sensor deployment and integration | Months 1–3 | Net negative — capital and IT labor expenditure with no benefit yet | Sensor installation, CMMS/ERP integration, data pipeline configuration |
| Model training and threshold calibration | Months 3–7 | Net negative — platform costs active, downtime reduction not yet materializing | Alert threshold tuning, false-alarm reduction, operator training |
| Early production results | Months 7–9 | Approaching breakeven — first confirmed avoided failures | Validate predictions against actual outcomes; refine model |
| Full production deployment (single site) | Months 9–12 | Positive cash flow beginning — documented downtime avoidance accumulating | Steady-state operations; begin building case for multi-site scaling |
| Multi-site scaling | Months 12–24+ | Positive NPV — scaling costs partially offset by reuse of trained models | Replicate deployment across additional assets and sites |
The practical implication for the ROI model is that year-one cash flow will be net negative for most deployments. The payback period should be calculated from the start of investment, not from the point when the system first produces an avoided failure. A three-year NPV model that shows net-negative year one, breakeven in year two, and positive NPV by year three is more credible than a model that front-loads benefits.
This timeline structure also addresses the scaling problem directly. McKinsey found that only 44% of manufacturers are conducting site-wide implementation of Industry 4.0 solutions, with most organizations unable to move beyond isolated pilots. The most common reason is that the original business case was built on pilot-stage costs and results — it didn't account for the incremental investment required to scale across additional sites and asset classes. A multi-year model that explicitly shows scaling costs and the corresponding benefit expansion is the tool that breaks this cycle.
Getting Finance Sign-Off: Framing the Business Case as Supply Chain Risk Mitigation
Finance teams that are not familiar with maintenance economics will not engage with a business case framed around CMMS cost reduction. They will, however, engage with supply chain disruption cost avoidance — because that connects directly to metrics they already own and monitor.
The correct framing for a finance audience is: this investment reduces the probability and cost of supply chain disruption events that are currently generating expediting premiums, SLA penalty exposure, and safety stock carrying costs. The maintenance cost reduction is an additional benefit, but it is not the primary justification.
When presenting to finance and executive stakeholders, connect the ROI model outputs directly to S&OP implications.
- Service level risk: Quantify the current probability of a customer SLA breach attributable to equipment-driven production shortfalls. Show how predictive maintenance reduces that probability and the associated penalty exposure.
- Safety stock policy: If your demand planning model currently carries excess safety stock to buffer against equipment unreliability, show the working capital release available when that buffer can be reduced. This is a direct balance sheet benefit that finance will recognize.
- Customer commitment exposure: Identify the revenue at risk if a critical asset failure triggers a customer delivery failure. Frame the predictive maintenance investment as insurance against that revenue exposure.
- Expediting cost trend: If your TMS data shows a pattern of reactive expediting spend following equipment failures, present that trend as a recoverable cost. Finance teams respond to documented cost patterns more readily than to projected savings.
The three output metrics from the ROI model — payback period, 3-year NPV, and annual cost avoidance — should be presented with explicit acknowledgment of the ramp-up timeline and the assumptions behind each benefit component. A model that openly documents its assumptions and limitations is more credible than one that presents a single optimistic scenario.
Comments
Join the discussion with an anonymous comment.