What This Record Covers
This record addresses a single, bounded operational problem: applying AI techniques to supplier selection decisions within indirect spend categories. It is not a general overview of AI in procurement. Every section answers a specific question — does this technique apply to indirect spend supplier selection, and under what conditions?
Indirect spend supplier selection differs structurally from direct spend in ways that directly limit AI automation potential. Direct spend categories — raw materials, components, contract manufacturing — tend to have high spend concentration per supplier, repeatable decision criteria, and years of documented performance data. Indirect spend categories do not.
Indirect spend is characterized by high category fragmentation (hundreds of sub-categories, each with different evaluation logic), low spend per individual supplier, weaker historical outcome data (fewer formal RFP evaluations per category per year), and greater reliance on qualitative judgment — particularly in categories like professional services, where scope ambiguity and relationship context dominate the selection decision.
Technique-to-Sub-Category Applicability Matrix
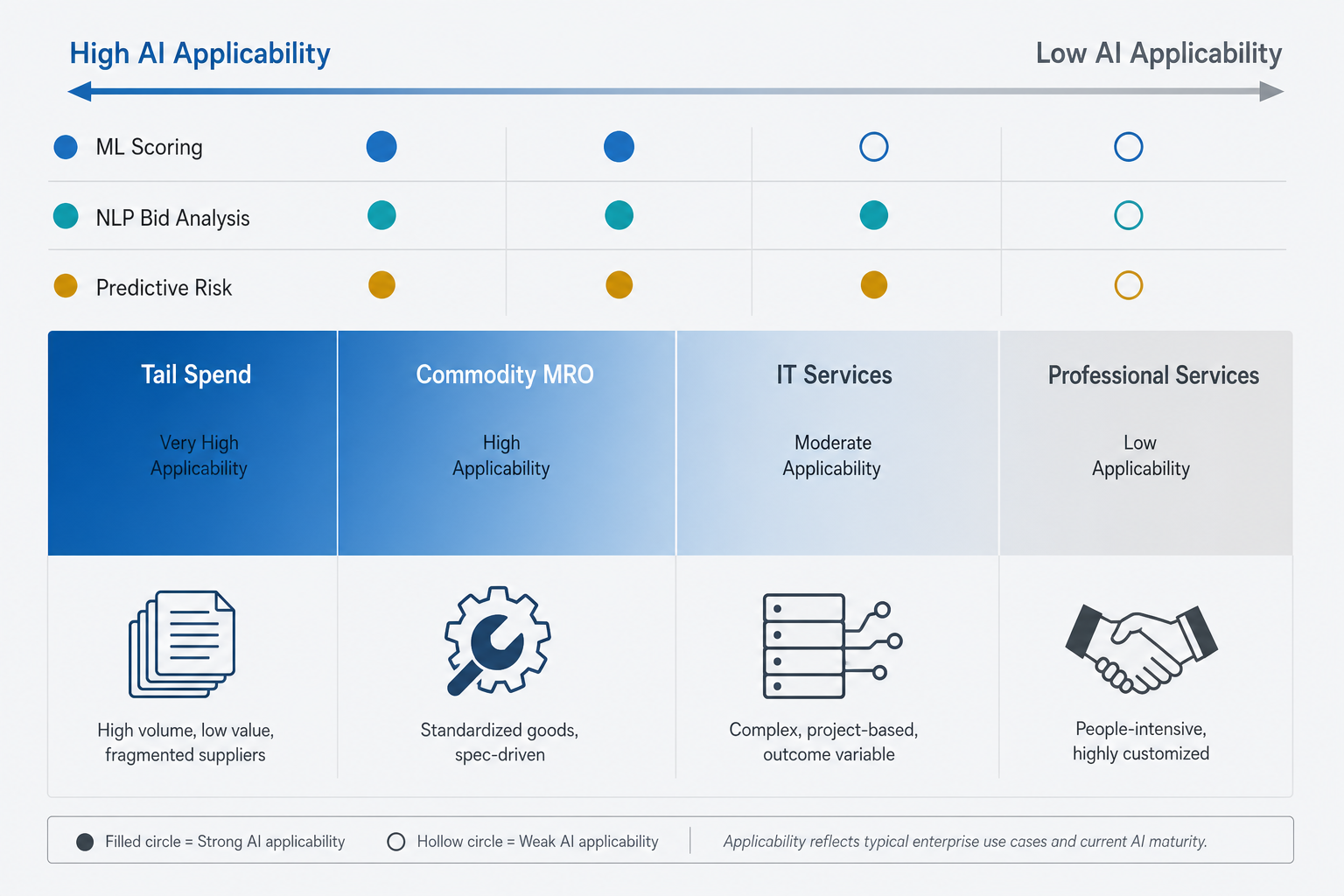
Three AI techniques are relevant to indirect spend supplier selection. Each has different data requirements, different strengths, and different applicability ceilings depending on the indirect sub-category.
- Supervised ML scoring: trains on labeled historical RFP evaluation data to score and rank suppliers against predefined criteria. Requires sufficient historical evaluations with documented outcomes per category.
- NLP bid analysis: ingests bid documents, extracts structured data, validates compliance, and applies weighted scoring. Requires structured scoring rubrics defined before deployment — the AI applies the rubric, it does not create it.
- Predictive risk scoring: combines supplier financial data, ESG signals, news sentiment, and sanctions screening to generate a forward-looking risk profile. Requires access to external data feeds and a structured supplier master.

| Indirect Sub-Category | Supervised ML Scoring | NLP Bid Analysis | Predictive Risk Scoring | Overall AI Readiness |
|---|---|---|---|---|
| Tail Spend | High — volume and repeatability support training | High — structured bid formats, price-dominant logic | Moderate — supplier data often thin for micro-suppliers | High |
| Commodity MRO | High — repeatable criteria, historical evaluations available | High — technical specs are structured and scoreable | High — supplier financial data more accessible | High |
| IT Services | Moderate — criteria more complex, but structured enough | Moderate — SOW variability requires rubric discipline | High — vendor financial and security risk data available | Moderate |
| Professional Services | Low — insufficient labeled evaluations, qualitative dominance | Low — scope ambiguity limits structured extraction | Moderate — risk scoring applicable but selection still human-driven | Low |
NLP bid analysis illustrates why predefined criteria are a prerequisite, not a product feature. The process — document ingestion, entity extraction, semantic normalization, compliance validation, weighted scoring, TCO extraction, and risk assessment — is technically sophisticated. But the weighted scoring step requires evaluators to configure the scoring dimensions before the model runs. AI analyzes bids against structured, rule-based factors such as technical compliance, pricing competitiveness, and delivery timelines — but complex qualitative dimensions still require human review. If the scoring rubric is undefined or inconsistently applied, the NLP layer has no reliable criteria to enforce.
Data Prerequisites by Technique
Data readiness is a deployment gate, not a follow-on activity. Deploying AI supplier selection before the required data conditions are met does not produce a degraded version of the intended outcome — it produces unreliable outputs that erode procurement team trust in the tool.
A McKinsey survey found that 21% of procurement leaders rate their data infrastructure maturity as low, with less than 70% of spend data centralized. Even centralized data is often uncleaned or poorly categorized. This is not a minor implementation challenge — it is the primary technical barrier to scaling AI across indirect spend categories.
| Technique | Minimum Data Condition | Common Gap in Indirect Spend | Realistic Automation Ceiling |
|---|---|---|---|
| Supervised ML Scoring | 12–18 months of labeled historical RFP evaluations per category, with documented supplier outcomes | Most indirect categories lack sufficient labeled evaluations; evaluations that exist are often informal or undocumented | ~80% of classification automatable in high-readiness categories; 20% requires human review |
| NLP Bid Analysis | Structured scoring rubrics defined before deployment; bid documents in machine-readable format (PDF, structured Word) | Rubrics often undefined or inconsistently applied; bid formats vary widely across suppliers | High for structured bids in commodity categories; low for narrative-heavy professional services proposals |
| Predictive Risk Scoring | External data feeds (financial filings, ESG databases, news sentiment APIs); clean supplier master with normalized entity names | Supplier master quality is frequently poor; micro-suppliers in tail spend may have no external data coverage | High for mid-to-large suppliers with public data; low for small or regional indirect vendors |
Only 37% of organizations report trusting their supplier data. A unified, trusted supplier data foundation is not a byproduct of AI deployment — it is a prerequisite for it. Organizations that attempt to train ML models on fragmented, inconsistently categorized indirect spend data will produce models that amplify the existing data problems rather than overcome them.
Applicability Conditions: When to Deploy and When Not To
The conditions under which AI-assisted supplier selection is viable are specific and testable before deployment begins. The following conditions indicate a category is ready for AI deployment:
- High transaction volume: sufficient sourcing events per year to generate training signal and to make automation economically justified.
- Repeatable decision criteria: evaluation dimensions are consistent across sourcing events and can be defined in a scoring rubric before deployment.
- Price-dominant or specification-dominant logic: selection decisions are primarily driven by quantitative factors (price, delivery time, technical compliance) rather than qualitative relationship or strategic fit judgments.
- Organized historical data: past RFP evaluations are documented with supplier outcomes, spend is centralized in the ERP or P2P system, and the supplier master is clean and normalized.
- Spend flows through procurement channels: the category's spend is captured in systems of record, not dispersed across P-cards, shadow purchasing, or departmental buying outside procurement visibility.
The following conditions indicate a category is not ready for AI-driven supplier selection, regardless of the tool being evaluated:
- Qualitative judgment dominance: categories where strategic fit, relationship history, cultural alignment, or scope interpretation are primary selection factors — consulting, legal, marketing, executive search.
- Scope ambiguity: professional services engagements where the scope of work is negotiated iteratively and cannot be reduced to a structured requirements matrix before the sourcing event.
- High maverick spend: categories where a substantial portion of actual spend bypasses procurement channels entirely, making historical data unrepresentative of real sourcing patterns.
- Decentralized P-card or shadow spend: where individual business units purchase independently, creating data gaps that make training data structurally unreliable.
Professional services warrants specific attention because it is both a large category and a low-readiness one. Professional services typically represent 10–15% of total organizational spend, making it one of the largest indirect spend categories by dollar value. Yet the structural conditions for AI-driven selection are poor: scope ambiguity is endemic, qualitative judgment dominates, and — critically — approximately 40–60% of professional services spend occurs outside approved procurement channels. When nearly half the category's spend is invisible to the ERP and P2P systems that would supply training data, any ML model trained on that data will systematically misrepresent actual sourcing patterns.
Known Failure Modes
Failure modes in AI-assisted supplier selection are not edge cases. They are predictable patterns that emerge from specific structural conditions. Understanding them before deployment is more useful than diagnosing them after a failed rollout.

Failure Mode 1: Training Data Encodes and Reproduces Incumbent Bias
If historical sourcing decisions favored incumbent suppliers — for reasons of relationship, geography, or organizational inertia rather than objective performance — then ML models trained on that history will reproduce the same preference pattern. The model learns that incumbents win, not that incumbents perform best.
GEP similarly identifies that historic procurement data may contain embedded human biases, and that AI models can amplify rather than correct these patterns. The practical implication: before training a supervised ML model on historical sourcing data, the training set must be audited for incumbent concentration and systematically corrected — not assumed to be objective because it is historical.
Failure Mode 2: Category Fragmentation Produces Insufficient Training Examples
Indirect spend is not one category — it is hundreds. A supervised ML model trained on all indirect spend combined will not perform reliably on any specific sub-category, because the evaluation criteria, supplier characteristics, and decision logic differ substantially between, say, facilities maintenance and IT staffing.
Training separate models per sub-category is the correct approach — but it requires sufficient labeled historical evaluations per category. Most indirect spend categories, even in large enterprises, do not generate enough formal sourcing events per year to produce a training set that a supervised ML model can learn from reliably. The fragmentation that defines indirect spend is exactly what makes per-category ML models difficult to train.
Failure Mode 3: Shadow Spend Gaps Make Historical Data Unrepresentative
When a significant portion of category spend occurs outside procurement-managed channels — through P-cards, departmental purchasing, or informal vendor relationships — the data captured in ERP and P2P systems represents only the portion of spend that went through formal channels. A model trained on this data learns from a biased sample.
This problem is most acute in professional services, where maverick spend rates are structurally high. But it also affects IT services, marketing, and any indirect category where business units have historically operated with significant purchasing autonomy. The shadow spend gap is not a data quality problem that can be fixed by cleaning existing records — it requires bringing off-channel spend into managed procurement processes before the data becomes usable for AI training.
Implementation Sequencing and Governance Model
The sequencing of category deployment is not a preference — it is a risk management decision. Starting with the highest-readiness categories builds the data infrastructure, organizational trust, and model governance capabilities that make subsequent category deployments viable.
- Start with commodity MRO and tail spend consolidation. These categories offer the highest data readiness, most repeatable decision criteria, and clearest price-dominant logic. They also generate the volume of transactions needed to train and validate models quickly.
- Progress to IT services and software procurement. Evaluation criteria are more complex, but structured enough for NLP bid analysis and predictive risk scoring. SOW variability requires additional rubric discipline before NLP deployment.
- Treat professional services as AI-supported, not AI-driven. Risk scoring and rate benchmarking are appropriate AI applications. Selection decisions remain human-driven until procurement channel discipline and historical data quality improve.
Starting with professional services is a predictable failure pattern. The category's structural characteristics — scope ambiguity, maverick spend, qualitative judgment dominance — mean that AI models deployed there will produce low-confidence outputs, generate procurement team skepticism, and consume implementation budget without producing reliable results.
Two governance models apply to indirect spend AI deployment, and the distinction between them determines how much human oversight is required at each stage:
| Governance Model | Definition | Applicable Sub-Categories | When to Use |
|---|---|---|---|
| Human-in-loop | Every AI output is reviewed by a procurement professional before any action is taken | Professional services, IT services (early deployment), any category with low model confidence | Low-volume, high-value decisions; early deployment phases; categories with qualitative judgment requirements |
| Human-on-loop | AI operates autonomously for routine tasks; humans supervise outputs and intervene on exceptions | Commodity MRO, tail spend (mature deployment with validated models) | High-volume, repeatable categories with demonstrated model accuracy and established exception-handling protocols |
Distinguishing ML-Based Scoring from Rule-Based Automation
Vendor marketing in the procurement AI space frequently conflates two distinct technique categories: ML-based supplier scoring and rule-based procurement automation. These are not variants of the same approach — they have different data requirements, different deployment complexity, different governance implications, and different failure modes.
Rule-based automation — P-card spend routing, catalog purchasing, RPA-based invoice matching, automated PO generation within defined parameters — executes predefined logic consistently and at scale. It does not learn from outcomes, does not improve with additional data, and does not require labeled training examples. It is highly reliable within its defined parameters and highly brittle outside them.
ML-based supplier scoring learns patterns from historical labeled data and applies those patterns to new sourcing decisions. It improves with additional training data, degrades when training data is biased or sparse, and requires ongoing model monitoring to detect drift. It is more flexible than rule-based automation but substantially more demanding in terms of data prerequisites and governance requirements.
Metrics Affected and Applicability Conditions for Cross-Reference
When deployed in applicable indirect sub-categories with adequate data conditions, AI-assisted supplier selection affects the following procurement metrics:
- Supplier evaluation cycle time: NLP bid analysis and automated scoring reduce the time from bid receipt to shortlist generation in structured categories.
- Scoring consistency: ML-based and NLP-based scoring applies criteria uniformly across all bids, reducing evaluator variability and the influence of familiarity bias.
- Bid compliance rate: automated compliance validation against a structured requirements matrix identifies non-compliant bids before human review begins.
- Total cost of ownership accuracy: TCO extraction from bid documents — including delivery terms, payment conditions, and ancillary costs — produces more complete cost comparisons than manual review.
- Incumbent concentration risk: AI scoring applied consistently across sourcing events surfaces qualified alternative suppliers that informal evaluation processes would overlook.
On broader category savings: BCG's February 2025 research identifies three-year AI-enabled savings potential across indirect categories — IT development at 23–45%, administrative and professional services at 17–37%. These figures represent GenAI-enabled category savings broadly, not supplier selection automation specifically. They should not be used as a direct projection for AI supplier selection ROI without accounting for the full scope of AI-enabled procurement transformation those figures describe.
Comments
Join the discussion with an anonymous comment.