Why AI Supplier Risk Scoring Deployments Fail at the Data Layer
The gap between what AI supplier risk scoring tools promise and what procurement organizations actually achieve in production is not primarily a technology problem. According to the Hackett Group's 2025 CPO Agenda, only 4% of procurement AI pilots reach meaningful large-scale deployment. That figure covers all procurement AI — not supplier risk scoring specifically — but the pattern it describes is consistent with what practitioners encounter when they attempt to move from a promising pilot to a scoring system that procurement teams actually trust and use.
The readiness problem is well-documented on the organizational side too. Gartner's 2025 Leadership Vision for CPOs, as cited by Art of Procurement, found that 74% of procurement leaders report their data is not AI-ready. That statistic does not describe a technology shortfall. It describes an organizational condition that no vendor's model can compensate for.
The failure mode is consistent across deployments: a pilot runs against a curated subset of supplier records, produces plausible-looking scores, and earns stakeholder approval. Then the organization attempts to scale to its full supplier base and discovers that the data conditions that made the pilot work — clean supplier records, consistent transaction history, integrated external feeds — do not exist at production scale. The scoring system either produces scores that procurement teams do not trust, or it produces no scores at all for large portions of the supplier base.
A supplier risk score generated from incomplete data erodes professional confidence in a tool quickly and permanently.
That observation, drawn from practitioner accounts of AI adoption failures in procurement, captures why the data readiness question matters so much: once a scoring system produces a visible error — flagging a healthy supplier as high-risk because of mismatched records, or clearing a deteriorating supplier because its delivery history lives in a disconnected system — the credibility damage is difficult to reverse.
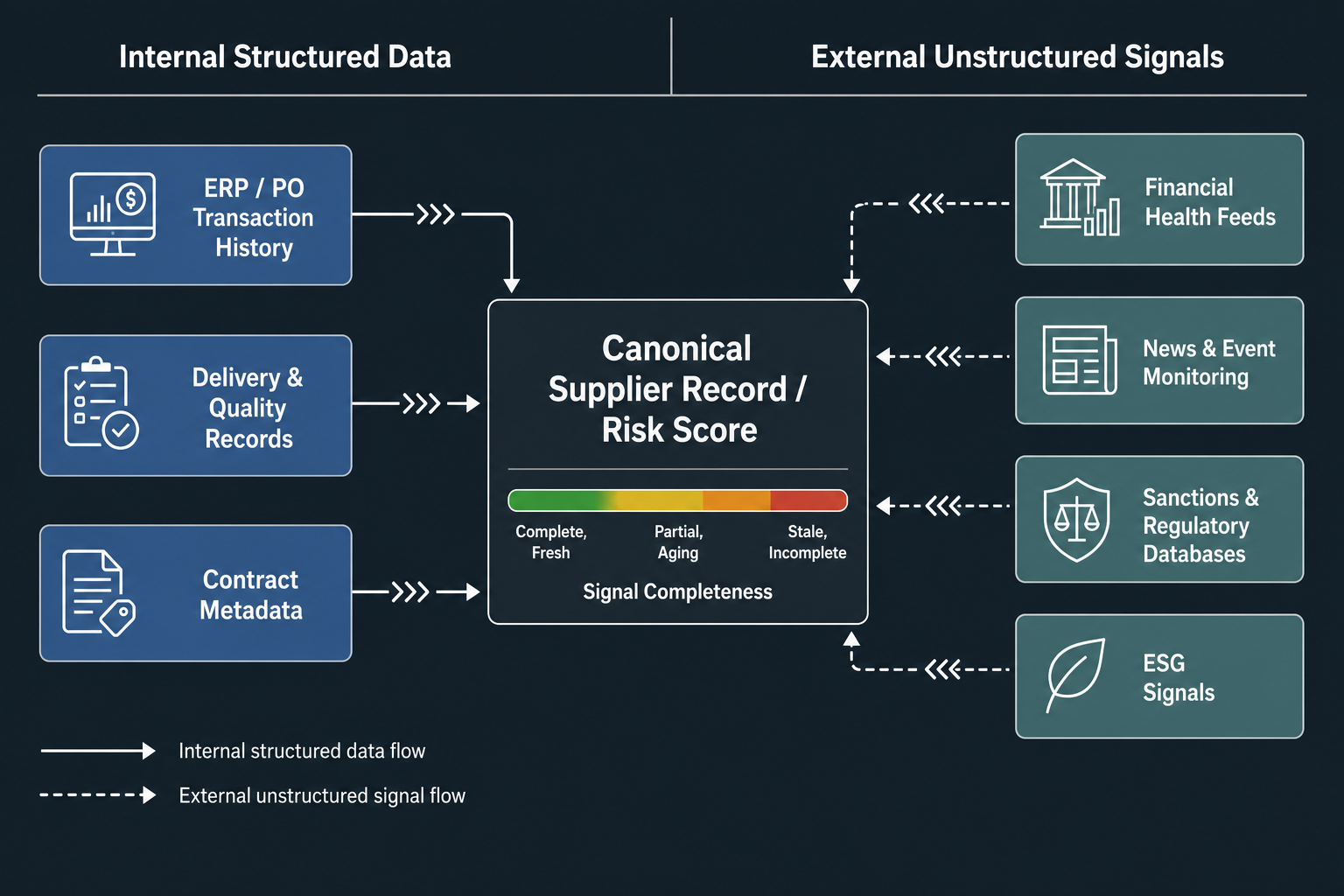
The Two-Layer Data Model: Internal Records and External Signals
A functioning AI supplier risk scoring system draws on two distinct data layers. Neither layer alone produces reliable scores. The first layer is internal structured data — the records that procurement and finance systems already hold: purchase order history, delivery and quality performance logs, contract metadata, and supplier master data. The second layer is external unstructured signals — financial health indicators, news and event monitoring, sanctions and regulatory databases, and ESG compliance signals sourced from outside the organization.
The internal layer provides the longitudinal performance baseline: how a supplier has actually behaved across transactions, lead times, and quality metrics over time. The external layer provides the forward-looking context: what is happening to that supplier's financial position, regulatory standing, and operational environment right now. A score built only on internal history misses emerging risks that have not yet affected delivery performance. A score built only on external signals lacks the operational grounding to distinguish a genuinely deteriorating supplier from one that appears in news coverage for unrelated reasons.

The integration between the two layers is not a post-launch enhancement. It is an architectural prerequisite. Supplier data tends to live in silos — delivery performance in one system, financial health somewhere else, compliance status in a third, and external signals not integrated at all. When these sources are not connected, the scoring model is working from an incomplete picture by design, and the scores it produces reflect that incompleteness whether or not the output surface makes it visible.
- Internal structured layer: ERP/PO transaction history, delivery and quality performance records, contract metadata, supplier master data with identity and relationship mapping.
- External signal layer: financial health feeds, news and event monitoring, sanctions and regulatory databases, ESG compliance signals.
- Integration requirement: both layers must be connected to the scoring model before production deployment — not sequentially added after a pilot.
Internal Structured Data Requirements
The internal data layer has four primary components. Each has distinct completeness requirements, and the failure mode for each is different.
Supplier Master Data
Supplier master data is the foundation that every other internal data component depends on. The scoring model needs a canonical supplier record — a stable, consistent representation of each supplier that includes a unique identifier, legal entity name, parent-child relationship mapping (to handle subsidiaries, acquired entities, and regional operating units), and classification attributes such as category, geography, and spend tier.
In practice, supplier master data is frequently the most degraded component in the internal layer. Duplicate records, inconsistent naming conventions across business units, and missing parent-entity linkages are common. The scoring model cannot compensate for these gaps — it will treat fragmented records as separate suppliers and produce separate (often contradictory) scores for what is actually a single entity.
Purchase Order and Transaction History
ML-based pattern detection requires sufficient transaction depth to distinguish signal from noise. As a practitioner-range estimate, 12 to 24 months of purchase order history is typically needed before a model can reliably identify trends in supplier behavior — cost escalation patterns, lead time drift, order fulfillment rate changes. Below that threshold, the model is operating on too thin a sample to produce scores that are meaningfully different from a rules-based tier assignment.
Transaction records should include supplier ID, part or service category, confirmed delivery date versus actual delivery date, unit price, and quantity. Consistent supplier keys across ERP exports, forecasts, and procurement systems are required to prevent join errors when the scoring model aggregates records across sources. A transaction history that cannot be reliably linked back to a canonical supplier identity is effectively unusable for scoring purposes.
Delivery and Quality Performance Records
On-time in-full (OTIF) rates and lead time variability are among the most informative internal signals for supplier risk detection — but only when recorded at sufficient granularity. Average lead time is a weak signal. Lead time variability is a much stronger one.
A supplier whose average lead time holds steady at 12 days but whose variability widens from ±1 to ±5 days represents a materially different operational risk than the average suggests. Similarly, a 3–5 point drop in OTIF over two consecutive months is rarely random noise. These are the patterns that AI pattern detection is designed to surface — but only if the underlying delivery records are captured at the order-line level with timestamps, not aggregated into monthly summary metrics before they reach the scoring system.
Contract Metadata
Contract metadata — expiration dates, renewal terms, pricing escalation clauses, SLA commitments, and penalty provisions — provides the scoring model with the structural context needed to interpret performance data correctly. A supplier approaching contract expiration with declining OTIF scores is a different risk profile than one with the same OTIF trend but a recently renewed long-term agreement. Without contract metadata, the scoring model cannot make that distinction.
| Internal Data Component | Minimum Requirement | Common Gap | Impact if Missing |
|---|---|---|---|
| Supplier master data | Canonical identifier, legal entity name, parent-child mapping | Duplicate records, inconsistent naming across BUs | Fragmented scores for same supplier; misleading risk classifications |
| PO and transaction history | 12–24 months depth; supplier ID, delivery dates, price, quantity | Shallow history for newer suppliers; missing line-level detail | Model cannot distinguish trend from noise; scores revert to rules-based tiers |
| Delivery and quality records | Order-line level OTIF and lead time with timestamps | Aggregated monthly summaries only; no variability capture | Variability signals missed; deteriorating suppliers appear stable |
| Contract metadata | Expiration dates, SLA terms, renewal status | Contracts in unstructured repositories; not linked to supplier ID | Performance context lost; risk interpretation errors |
External Signal Requirements: Financial Health, News, Sanctions, and ESG
External signals give the scoring model visibility into conditions that internal performance records cannot detect until they have already affected delivery. A supplier with acceptable historical OTIF but deteriorating payment terms, a credit downgrade, or a sanctions listing is a future operational problem that internal data will only confirm after the fact.
The external layer covers four signal categories. Each has distinct sourcing requirements and update cadence implications.
- Financial health feeds. Credit signals, payment behavior trends, and financial stability indicators from commercial data providers (D&B, Moody's, and equivalent sources). These signals provide early warning of liquidity stress before it manifests in delivery performance. Update cadence: near-real-time or daily refresh is required for this category to retain predictive value.
- News and event monitoring. Geopolitical disruptions, operational incidents (facility fires, labor actions, port closures affecting key supplier geographies), and leadership changes that affect operational continuity. NLP-based monitoring of news sources and regulatory filings surfaces these signals faster than periodic audits. Update cadence: continuous or near-real-time.
- Sanctions and regulatory compliance databases. OFAC, EU sanctions lists, export control registries, and debarment databases. A supplier appearing on a sanctions list requires immediate action — this signal category has the least tolerance for stale data. Update cadence: daily minimum; real-time where integration supports it.
- ESG compliance signals. Environmental compliance records, labor practice assessments, and supply chain transparency disclosures. These signals typically update at lower frequency than financial or sanctions data, but they are increasingly required for regulatory compliance in EU-facing supply chains. Update cadence: quarterly to monthly for most ESG inputs.
| Signal Category | Primary Sources | Required Update Cadence | Stale Data Risk |
|---|---|---|---|
| Financial health | D&B, Moody's, credit bureaus, payment behavior feeds | Daily to real-time | High — credit deterioration can precede delivery failure by weeks |
| News and event monitoring | News APIs, regulatory filings, NLP-processed media | Continuous to near-real-time | High — operational disruptions are time-sensitive |
| Sanctions and regulatory | OFAC, EU sanctions lists, export control registries | Daily minimum; real-time preferred | Critical — compliance exposure from stale sanctions data is immediate |
| ESG compliance | Regulatory disclosures, third-party ESG assessors | Quarterly to monthly | Medium — ESG status changes more slowly but is increasingly compliance-relevant |
Supplier Identity Resolution: The Most Underestimated Prerequisite
Of all the data prerequisites for a functioning supplier risk scoring system, supplier identity resolution is the one most consistently underestimated during planning and most frequently cited as the cause of post-deployment failure.
The problem is structural. In most large organizations, supplier records exist independently in at least three systems: the ERP (which holds transaction and payment data), the procurement platform (which holds sourcing and contract data), and the finance or legal system (which holds entity-level agreements and compliance records). Each system may have created its own supplier record at a different time, using different naming conventions, different levels of legal entity specificity, and different handling of subsidiaries, acquired companies, and regional operating units.
When supplier identities are fragmented across procurement, finance, and legal systems, risk scores become misleading. A composite score built from mismatched records may aggregate the performance data of two different suppliers into one score, or split the records of a single supplier into two separate (and individually incomplete) profiles. Both errors produce classifications that appear valid in the output but are wrong in ways that are not immediately visible to the procurement team relying on them.
A canonical supplier identity model requires three components:
- Stable unique identifiers. A single persistent ID per legal entity that is used consistently across all systems. DUNS numbers, LEI codes, or internally assigned canonical IDs all work — what matters is that the identifier is applied consistently and does not change when a supplier record is updated in one system.
- Deterministic merge rules. Documented logic for how duplicate records are identified and resolved — not manual case-by-case judgment. Merge rules should specify how to handle name variations, address discrepancies, and the relationship between a parent entity and its subsidiaries.
- Parent-child relationship mapping. Explicit linkage between subsidiary entities and their parent organizations. This is particularly important for risk scoring because financial health and sanctions exposure are typically assessed at the parent entity level, while delivery performance is measured at the subsidiary or facility level. Without this mapping, a financially distressed parent may not surface in the risk score of a subsidiary that is performing well operationally.
Data Quality Thresholds and Freshness Requirements
Data quality for supplier risk scoring has two distinct dimensions: completeness (what fields are populated and at what coverage rate) and freshness (how recently the data was updated). Both dimensions affect score reliability, but they degrade it in different ways and at different rates.
Completeness failures tend to produce systematic gaps — entire supplier segments with no score, or scores that are only partially populated because key fields are missing. Freshness failures tend to produce scores that appear complete but are based on outdated conditions. Of the two, freshness failures are more dangerous in operational use because they are less visible: a score that exists but reflects a supplier's financial position from 45 days ago looks identical to one that reflects yesterday's data.
One practical illustration of how freshness affects score computation: a scoring model that applies a freshness weighting to its inputs will mechanically reduce the confidence weight of any signal that has not been refreshed within its required cadence. The effect is that stale inputs do not simply persist unchanged — they actively degrade the computed score's reliability rating, which should surface as a confidence indicator rather than being silently absorbed into a score that looks authoritative.
| Data Component | Completeness Floor (indicative) | Freshness Requirement | Effect of Breach |
|---|---|---|---|
| Supplier master data | 100% of active suppliers with canonical ID and legal entity name | Updated on entity change events | Score cannot be generated; orphaned transaction records |
| PO transaction history | All transactions linked to canonical supplier ID | Batch update: daily to weekly | Pattern detection degrades; trend signals weaken |
| Delivery/quality records | Order-line level; no monthly-summary-only aggregation | Batch update: daily | Variability signals lost; deterioration masked by averages |
| Financial health feeds | Coverage across all Tier 1 and critical Tier 2 suppliers | Daily to real-time | Emerging financial stress missed; score reflects outdated position |
| Sanctions databases | Full coverage; no supplier excluded from screening | Daily minimum | Compliance exposure from undetected sanctions listing |
| News and event monitoring | All active suppliers in scope | Continuous to near-real-time | Operational disruptions missed until they affect delivery |
One practical rule for high-severity scoring decisions: low-quality or unverified signals should not be allowed to drive escalations or procurement holds. If a signal's completeness or freshness falls below the threshold for a given risk dimension, that dimension should be flagged as uncertain rather than scored at face value. This requires the scoring system to surface data quality metadata alongside the score itself — a capability that should be evaluated explicitly during vendor selection.
ERP and Source-to-Pay Integration Conditions
The technical integration between a supplier risk scoring system and the procurement organization's existing systems is where many deployments stall after a successful pilot. Pilots typically run against a data extract or a sandboxed subset of the ERP. Production deployment requires a live, reliable, continuously refreshed connection to the systems that hold the data the model depends on.
Legacy systems with limited API capabilities, multiple ERP instances across business units, and disparate procurement tools requiring integration are consistently identified as the leading integration complexity barriers. Multi-instance SAP or Oracle environments — common in organizations that have grown through acquisition — are a particularly frequent blocker because each instance may have different data models, different supplier ID conventions, and different API maturity levels. Connecting a scoring system to three ERP instances with inconsistent supplier master data is not a connector configuration task; it is an integration engineering project.
Three specific integration conditions should be assessed before production rollout:
- Idempotent writes and state consistency. When the scoring system writes risk status back to procurement or finance systems, those writes must be idempotent — repeated execution of the same write should not create duplicate records or inconsistent states. If integration fails silently, teams make decisions using stale risk context — a failure mode that is worse than no scoring system because it creates false confidence.
- API maturity and connector reliability. Not all ERP integrations are equally mature. A vendor that offers a certified SAP S/4HANA connector is in a materially different position than one offering a generic REST API that requires custom development to connect to your ERP version. Assess connector maturity specifically for your ERP version and instance configuration, not based on general platform compatibility claims.
- Silent integration failure detection. Integration pipelines fail without alerting the end user. A data feed that stopped refreshing three days ago will not announce itself — the scoring system will continue to display scores that now reflect outdated conditions. Production deployments require monitoring on the integration layer itself, with alerting when refresh cadence falls outside expected parameters.
The systems the scoring model needs to connect to extend beyond the primary ERP. A complete integration scope for production deployment typically includes: the ERP (transaction and payment data), the source-to-pay or procurement platform (sourcing events, contract data, supplier onboarding records), the logistics or 3PL system (delivery performance data), the finance system (payment behavior, accounts payable aging), and the compliance management system (sanctions screening, audit records). Each connection adds integration complexity and a potential failure point.
Organizational Data Readiness Checklist
The following self-assessment framework is designed for procurement teams before they commit to a vendor selection or build path. It maps directly to the data and integration conditions covered in this guide. Each item should be assessed against your current state, not your planned state — the purpose is to identify gaps that need to be closed before deployment begins, not to document aspirations.

| Readiness Dimension | Assessment Question | Deployment-Ready | Remediation Needed | Deployment Blocker |
|---|---|---|---|---|
| Supplier master completeness | Do all active suppliers have a canonical identifier and legal entity name in a single authoritative system? | Yes, with <2% exceptions | Gaps in one BU or category; remediation underway | No canonical system; records distributed across BUs with no merge logic |
| Transaction history depth | Is 12+ months of PO history available at the order-line level, linked to canonical supplier IDs? | Yes, for ≥90% of active spend | Available for strategic suppliers only; tail spend gaps | History exists but is not linked to canonical IDs; or <6 months available |
| Identity resolution status | Has a canonical supplier model with deterministic merge rules and parent-child mapping been built and validated? | Yes, tested and in production | In progress; partial coverage | Not started; fragmented records across ERP, finance, and procurement |
| Delivery/quality records | Are OTIF and lead time records captured at order-line level with timestamps (not monthly summaries)? | Yes, for all active suppliers | For strategic suppliers; spot-buy suppliers not covered | Only monthly aggregates available; no line-level timestamps |
| External feed integration | Are financial health, sanctions, and news monitoring feeds integrated and refreshing at required cadence? | Yes, all three categories live | One or two categories integrated; others pending | No external feeds integrated; relying on periodic manual checks |
| ERP integration maturity | Have ERP connectors been assessed for your specific version and instance configuration? | Certified connector available and tested | Connector exists but requires custom development | No connector; custom API development required; multi-instance complexity unresolved |
| Integration failure monitoring | Is there alerting in place for when data refresh pipelines fall outside expected cadence? | Yes, with defined escalation path | Monitoring exists; escalation path not defined | No pipeline monitoring; failures would be silent |
Any item in the "Deployment Blocker" column should be resolved before vendor selection is finalized — not after. A vendor's model cannot compensate for a missing canonical supplier identity system or an unintegrated external feed. These are organizational infrastructure conditions, and they determine the ceiling of what any scoring system can achieve.
Items in the "Remediation Needed" column require a realistic remediation timeline as part of the deployment plan. If remediation is expected to take six months, the deployment timeline should reflect that — not assume the gaps will be closed in parallel with model configuration.
The supplier risk scoring category attracts significant investment — the Hackett Group data indicates average investments of $2.0 million per use case for supplier risk assessment and monitoring, with a 58% production rate among organizations that have reached this stage. That production rate is meaningfully higher than the 4% figure for procurement AI overall, which suggests that organizations that do reach production in this category have cleared the data and integration prerequisites. The path to joining that group runs through the readiness conditions described here, not through model selection.
Comments
Join the discussion with an anonymous comment.